Отказ от тестирования часто связан с критическим отношением к нему со стороны рекламных (особенно творческих) работников, а также с экономией денежных средств и времени. Тестирование может затормозить запуск рекламной кампании, а значит – и самого продукта. Вместе с тем очевидно, что при больших бюджетах тестирование помогает избежать многомиллионных ошибок. Оно также может быть полезным и для некрупных рекламодателей, для которых несложно подобрать простые, недорогие тесты. Как говорят классики рекламы, «тестирование может быть ограниченным или даже неудачным, но оно все равно даст что-то, от чего можно отталкиваться, чем можно руководствоваться».
Исследователи насчитывают несколько тысяч видов тестов. Не меньше существует и мнений о полезности и правильности проведения тех или иных тестов.
Один из основных вопросов оценочных иссл дований: «Что собственно тестировать?» Те же классики рекламы утверждали, что «эффект рекламы (за исключением рекламы посылторга) в основном не поддается измерению... Рекламодатели, конечно же, хотят иметь возможность учета, но рекламу часто приходится измерять методами более скромными и более неосязаемыми, чем хотелось бы. Боюсь, нам придется примириться с тем, что большая часть рекламы сможет полностью окупить себя только по прошествии длительного отрезка времени, а степень окупаемости невозможно проверить сколь-нибудь точно».
Действительно, выявить решающий фактор зависимости между самим рекламным обращением и его воздействием (или отсутствием этого воздействия) на отдельного человек весьма затруднительно. Например, в ходе одного из исследований группу, состоящую из управляющих по товару и управляющих службой рекламы фирм, руководителей рабочих групп рекламных агентств, творческих работников, специалистов по средствам рекламы и специалистов исследовательских служб, «попросили отобрать лучшие объявления из числа тех, что были уже тщательно проверены на рынке. Результат? Хотя экспертам, в общем-то, удалось установить, какие объявления должны были привлечь наибольшее число читателей, они не сумели определить, какие объявления помогли продать больше товара». Как уже говорилось ранее, кроме рекламы, слишком много других различных факторов влияет на продажи. А по утверждению авторитетнейших специалистов, «методов быстрого и несложного контроля многочисленных факторов, оказывающих влияние на сбыт, не существует».
Согласно мнению Ч. Сэндиджа, В. Фрайбургера и К.Ротцолла, «на реакцию влияет множество всевозможных “причин”, а каждая переменная раздражителя порождает множество “эффектов”. Одно и то же объявление может, к примеру, раздражать, информировать, забавлять, подкреплять уверенность, побуждать к действию, может оказаться полностью проигнорированным в момент контакта, а позднее его могут быстро забыть или частично припомнить, оно же может стать причиной перемены в отношении или осведомленности. Поэтому совершенно ясно, что, решая, какими параметрами ответной реакции воспользоваться, исследователь должен во многом руководствоваться здравым смыслом».
В связи с вышесказанным представляется очевидным, что объявление (прежде чем на него отреагируют) должно быть увидено. После контакта с рекламой человек также должен знать торговую марку или название компании, разбираться в свойствах, преимуществах и выгодах товара. У человека может появиться рациональная или эмоциональная предрасположенность к покупке определенного товара. К этому можно добавить мнение руководства одного из крупнейших мировых рекламодателей General Motors : «Эффективность будет прежде всего измеряться достоверностью, способностью использовать эмоции и убедительностью рекламы».
Тестированию можно подвергать именно определенные человеческие реакции. При этом оценке следует подвергать или одиночные параметры, или минимальный набор, так как попытки анализировать сразу слишком большое количество действующих параметров рекламы могут спутать результаты. Вместе с тем, чем больше в целом параметров будет протестировано, тем точнее будет конечный результат. «При тщательном анализе всего одного-двух периферийных аспектов эффективности рекламы результаты ее тестирования могут показаться слишком стерильными и нереальными для тех, кто должен будет пользоваться ими в процессе принятия решений. Если он некритично поставит знак равенства между степенью запоминаемости и воздействием или изменением отношения и сбытом, у него остается возможность положиться на веру, не дающую никаких гарантий».
Итак, для проверки эффективности завершенной или почти завершенной рекламы проводятся различные оценочные исследования или тесты. Они позволяют сэкономить средства за счет корректировки рекламы до того, как будут профинансированы средства ее распространения. Таким образом тестирование помогает избежать многомиллионных ошибок. Также оценочные исследования могут быть полезны и после размещения рекламы, например при оценке процессов влияния рекламы на текущие продажи.
Однако с точки зрения практиков не все исследования и не всегда имеют ценность. Иногда они могут не только помогать, но и вредить работе. Интуиция практиков может оказаться более точным инструментом, чем научные изыскания. Тесты и их результаты – это не сами решения, они лишь предоставляют практикам информацию, использование которой, совместно с эмпирическим опытом рекламного работника, дает возможность принимать взвешенные решения.
В настоящей главе были рассмотрены различные виды тестов, применяемы в рекламе, различные методы тестирования, критерии тестирования и этапы тестирования. Были рассмотрены также особенности тестирования рекламы в различных СМИ, для чего часто используются различные же подходы.
Особое внимание было уделено предварительному т стированию (претестированию), так как оно повышает вероятность подготовки наиболее эффективных текстов до того момента, как будут затрачены деньги на размещение рекламы.
Другой тип тестирования – посттестирование (или заключительное тестирование), со своей стороны, не имеет главного недостатка, присущего предварительному тестированию, – определенной доли искусственности. При заключительном тестировании поведение людей не искажается, оно естественно, реалистично. Во время заключительного тестирования учитывается ряд факторов, также серьезно влияющих на результаты. Прежде всего, это специфика средств распространения рекламы, время размещения рекламы, частота ее предъявления потребителям и т. д.
Если все рекламное сообщение, как правило, тестируют на способность стимулировать продажи, на убедительность, узнаваемость и запоминаемость продукта или марки, то рекламный текст обычно тестируют только на убедительность. В таких тестах внимание обращается в первую очередь на понимание заголовка, слогана, коды, ключевых слов.
Сегодня мы получаем новые инструменты для тестирования. Например, заголовки, ключевая слова можно успешно тестировать с помощью системы контекстной рекламы.
Каждый оценочный метод обладает специфическим сочетанием преимуществ и недостатков, а также разной стоимостью. Важным и очень простым, а главное, дешевым средством проверки эффективности рекламных текстов являются чек-листы (контрольные списки вопросов).
Видеоверсия лекции " Тестирование эффективности современной рекламы "
(готовится к публикации)
Более подробную информацию на эту тему можно найти в книге А. Назайкина
Каждый раз, когда мы заваливаем очередной релиз, начинается суета. Сразу появляются виноватые, и зачастую – это мы, тестировщики. Наверное это судьба – быть последним звеном в жизненном цикле программного обеспечения, поэтому даже если разработчик тратит уйму времени на написание кода, то никто даже не думает о том, что тестирование – это тоже люди, имеющие определенные возможности.
Выше головы не прыгнуть, но можно же работать по 10-12 часов. Я очень часто слышал такие фразы)))
Когда тестирование не соответствует потребностям бизнеса – то возникает вопрос, зачем вообще тестирование, если они не успевают работать в установленные сроки. Никто не думает о том, что было раньше, почему требования нормально не написали, почему не продумали архитектуру, почему код кривой. Но зато когда у вас дедлайн, а вы не успеваете завершить тестирование, то тут вас сразу начинают карать…
Но это было пару слов о нелегкой жизни тестировщика. Теперь к сути 🙂
После пару таких факапов все начинают задумываться, что не так в нашем процессе тестирования. Возможно, вы, как руководитель, вы понимаете проблемы, но как их донести до руководства? Вопрос?
Руководству нужны цифры, статистика. Простые слова – это вас послушали, покивали головой, сказали – “Давай, делай” и все. После этого все ждут от вас чуда, но даже если вы что-то предприняли и у вас не получилось, вы или Ваш руководитель опять получает по шапке.
Любое изменение должно поддерживаться руководством, а чтобы руководство его поддержало, им нужны цифры, измерения, статистика.
Много раз видел, как из таск-трекеров пытались выгружать различную статистику, говоря, что “Мы снимаем метрики из JIRA”. Но давайте разберемся, что такое метрика.
Метрика - технически или процедурно измеримая величина, характеризующая состояние объекта управления.
Вот посмотрим – наша команда находит 50 дефектов при приемочном тестировании. Это много? Или мало? Говорят ли Вам эти 50 дефектов о состоянии объекта управления, в частности, процесса тестирования?
Наверное, нет.
А если бы Вам сказали, что количество дефектов найденных на приемочном тестировании равно 80%, при том, что должно быть всего 60%. Я думаю тут сразу понятно, что дефектов много, соответственно, мягко говоря, код разработчиков полное г….. неудовлетворителен с точки зрения качества.
Кто-то может сказать, что зачем тогда тестирование? Но я скажу, что дефекты – это время тестирования, а время тестирования – это то, что напрямую влияет на наш дедлайн.
Поэтому нужны не просто метрики, нужны KPI.
KPI – метрика, которая служит индикатором состояния объекта управления. Обязательное условие – наличие целевого значения и установленные допустимые отклонения.
То есть всегда, строя систему метрик, у вас должна быть цель и допустимые отклонения.
Например, Вам необходимо (Ваша цель), чтобы 90% всех дефектов решались с первой итерации. При этом, вы понимаете, что это не всегда возможно, но даже если количество дефектов, решенных с первого раза, будет равняться 70% – это тоже хорошо.
То есть, вы поставили себе цель и допустимое отклонение. Теперь, если вы посчитаете дефекты в релизе и получите значение в 86% – то это конечно не хорошо, но и уже не провал.
Математически это будет выглядеть, как:
Почему 2 формулы? Это связано с тем, что существует понятие восходящих и нисходящих метрик, т.е. когда наше целевое значение стремится к 100% или к 0%.
Т.е. если мы говорим, к примеру, о количестве дефектов, найденных после внедрения в промышленной эксплуатации, то тут, чем меньше, тем лучше, а если мы говорим о покрытии функционала тест-кейсами, то тогда все будет наоборот.
При этом не стоит забывать о том, как рассчитывать ту или иную метрику.
Для того, чтобы получить необходимые нам проценты, штуки и т.д., нужно производить расчет каждой метрики.
Для наглядного примера я расскажу Вам о метрике “Своевременность обработки дефектов тестированием”.
Используя аналогичный подход, о котором я рассказал выше, мы также на основе целевых значений и отклонений формируем показать KPI для метрики.
Не пугайтесь, в жизни это не так сложно, как выглядит на картинке!

Что мы имеем?
Ну понятно, что номер релиза, номер инцидента….
Critical - коэф. 5,
Major - коэф. 3,
Minor - коэф. 1,5.
Далее необходимо указать SLA на время обработки дефекта. Для этого определяется целевое значение и максимально допустимое время ретестирования, аналогично тому, как я описывал это выше для расчета показателей метрик.
Для ответа на эти вопросы мы сразу перенесемся к показателю эффективности и сразу зададим вопрос. А как рассчитать показатель, если значение одного запроса может равняться “нулю”. Если один или несколько показателей будет равно нулевому значению, то итоговый показатель при этом будет очень сильно снижаться, поэтому возникает вопрос, как наш расчет сбалансировать так, чтобы нулевые значения, к примеру, запросов с коэффициентом тяжести “1” не сильно влияли на нашу итоговую оценку.
Вес - это значение, которое необходимо нам для того, чтобы сделать наименьшим влияние запросов на итоговую оценку с низким коэффициентом тяжести, и наоборот, запрос с наибольшим коэффициентом тяжести имеет серьезное влияние на оценку, при условии того, что мы просрочили сроки по данному запросу.
Для того, чтобы у вас не сложилось непонимания в расчетах, введем конкретные переменные для расчета:
х - фактические время, потраченное на ретестирование дефекта;
y - максимально допустимое отклонение;
z - коэффициент тяжести.
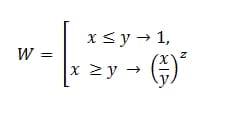
Или на обычно языке, это:
W = E СЛИ (x<=y,1,(x/y)^z)
Таким образом, даже, если мы вышли за установленные нами рамки по SLA, наш запрос в зависимости от тяжести не будет серьезно влиять на наш итоговый показатель.
Все как и описывал выше:
х – фактические время, потраченное на ретестирование дефекта;
y – максимально допустимое отклонение;
z – коэффициент тяжести.
h –
плановое время по SLA
Как это выразить в математической формуле я уже не знаю, поэтому буду писать программным языком с оператором ЕСЛИ.
R = ЕСЛИ(x<=h;1;ЕСЛИ(x<=y;(1/z)/(x/y);0))
В итоге мы получаем, что если мы достигли цели, то наше значение запроса равно 1, если вышли за рамки допустимого отклонения, то рейтинг равен нулевому значению и идет расчет весов.
Если наше значение находится в пределах между целевым и максимально допустимым отклонением, то в зависимости от коэффициента тяжести, наше значение варьируется в диапазоне .
Теперь приведу пару примеров того, как это будет выглядеть в нашей системе метрик.
Для каждого запроса в зависимости от их важности (коэффициент тяжести) имеется свой SLA.
Что мы тут видим.
В первом запросе мы на час всего лишь отклонились от нашего целевого значения и уже имеем рейтинг 30%, при этом во втором запросе мы тоже отклонились всего на один час, но сумма показателей уже равна не 30%, а 42,86%. То есть коэффициенты тяжести играют важную роль в формировании итогового показателя запроса.
При этом в третьем запросе мы нарушили максимально допустимое время и рейтинг равен нулевому значению, но вес запроса изменился, что позволяет нам более правильно посчитать влияние этого запроса на итоговый коэффициент.
Ну и чтобы в этом убедиться, можно просто посчитать, что среднее арифметическое показателей будет равно 43,21%, а у нас получилось 33,49%, что говорит о серьезном влиянии запросов с высокой важностью.
Давайте изменим в системе значения на 1 час.

при этом, для 5-го приоритета значение изменилось на 6%, а для третьего на 5,36%.
Опять же важность запроса влияет на его показатель.
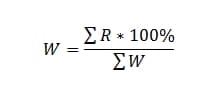
Все, мы получаем итоговый показатель метрики.
Что Важно!
Я не говорю о том, что использование системы метрик нужно делать по аналогии с моими значениями, я лишь предлагаю подход к их ведению и сбору.
В одной организации я видел, что был разработан собственный фреймворк для сбора метрик из HP ALM и JIRA. Это действительно круто. Но важно помнить, что подобный процесс ведения метрик требует серьезного соблюдения регламентных процессов.
Ну и что самое важное – только вы можете решить, как и какие метрики Вам собирать. Не нужно копировать те метрики, которые вы собрать не сможете.
Подход сложный, но действенный.
Попробуйте и возможно у вас тоже получится!
Александр Мешков – Chief Operations Officer в Перфоманс Лаб, – обладает опытом более 5 лет в области тестирования ПО, тест-менеджмента и QA-консалтинга. Эксперт ISTQB, TPI, TMMI.
В. В. Одинцова
Пользуясь многочисленными психодиагностическими методиками, мы редко задумываемся о качестве этих рабочих инструментов. И напрасно. Ведь любому практикующему психологу известно, что ни одно психологическое обследование невозможно без хорошего диагностического инструментария.
При этом популярные сборники психологических тестов, широко публикуемые в последнее время, к сожалению, не могут удовлетворить требованиям настоящего профессионала, который должен быть уверен в диагностических возможностях того инструмента, который он использует в своей работе. Поэтому, проблема поиска грамотно разработанной и надежной диагностической методики остается актуальной .
Основной задачей HR-Лаборатории Human Technologies является разработка качественной продукции. Одним из условий создания такой продукции являются периодические проверки тестовых методик на предмет их соответствия ряду психометрических требований (валидности, надежности, репрезентативности, достоверности). Для этого, после набора достаточного количества протоколов проводится статистический анализ тестовых методик.
Рассмотрим психометрический анализ (общая выборка которого составила 660 человек).
Данный тест, разработанный в 90-е гг., предназначен для экспресс-диагностики уровня выраженности пяти так называемых "больших" факторов темперамента и характера и используется для исследования личности взрослых людей с целью профотбора, профконсультации, определения направлений психологической помощи, комплектования групп, самопознания и т.п.
Основой универсальности "Большой пятерки факторов" является их кросс-ситуационность: факторы глобальной функционально-деятельностной оценки человека приложимы практически к любой ситуации социального поведения и предметной деятельности, в которых обнаруживаются устойчивые различия между людьми.
Опросник включает 75 пунктов по три варианта ответа в каждом.
ШКАЛЫ теста представляют собой точное воспроизведение факторов "Большой Пятерки" в их международном варианте (за исключением пятого фактора, который в ряде западных версий B5 обозначается как "открытость новому опыту - ограниченный практицизм"):
- экстраверсия - интроверсия
- согласие - независимость
- организованность - импульсивность
- эмоциональная стабильность - тревожность
- обучаемость - инертность
1. Проверка валидности
При проверке существующих шкал традиционным способом - путем расчета корреляций между ответами на вопросы и суммарным баллом по шкале - мы выяснили, что практически все пункты значимо коррелируют со "своими" шкалами со средним коэффициентом корреляции равным 0,35.
При проверке содержательной валидности теста были проанализированы формулировки заданий теста, содержательно отражающие соответствующую предметную область (область поведения) и имеющие значимую (положительную или отрицательную) корреляцию с суммарным баллом:
| Шкала | Пример заданий теста | Коэффициент корреляции |
| ЭКСТРАВЕРСИЯ | Для меня важно высказать свое мнение окружающим | (0,31) |
| Я люблю участвовать во всевозможных конкурсах, соревнованиях и т.п. | (0,41) | |
| Мне нравится ходить в гости и знакомиться с новыми людьми | (0,5) | |
| СОГЛАСИЕ | Большинству людей нельзя доверять | (-0,23) |
| Мои интересы для меня превыше всего | (-0,22) | |
| "Кто людям помогает, тот тратит время зря, хорошими делами прославиться нельзя" | (-0,3) | |
| "Каждый - сам за себя" - вот принцип, который не подведет | (-0,4) | |
| САМОКОНТРОЛЬ | Когда я ложусь спать, то уже наверняка знаю, что буду делать завтра | (0,37) |
| Взяв книгу, я всегда ставлю ее на место | (0,35) | |
| Перед ответственными делами я всегда составляю план их выполнения | (0,37) | |
| СТАБИЛЬНОСТЬ | Я легко краснею | (-0,28) |
| Если я уловил(а) возникновение нежелательной ситуации на работе, то это всегда вызывает у меня тягостное сомнение до тех пор, пока ситуация не прояснится | (-0,3) | |
| В конце дня я обычно устаю настолько, что любая мелочь начинает выводить из себя | (-0,32) | |
| Испортить мне настроение совсем просто | (-0,42) |
Анализ приведенных формулировок говорит о достаточно высокой содержательной валидности теста.
2. Проверка надежности
Надежность теста как средства измерения определяется низкой вероятностью ошибок измерения тестовых баллов и тем, в какой мере результаты измерений воспроизводятся при многократном использовании теста по отношению к данной группе испытуемых. Чтобы оценить вклад различных источников в ошибку измерения, необходимо использовать разные способы оценки надежности. Особый интерес представляет оценка внутренней согласованности теста, она обуславливает ту часть ошибки, которая связана с отбором заданий.
Оценка внутренней согласованности теста производилась посредством расчета альфа-коэффициента Кронбаха. Данный коэффициент представляет собой оценку надежности, базирующуюся на гомогенности шкалы или сумме корреляций между ответами испытуемых на вопросы внутри одной и той же тестовой формы.
В нашем случае рассчитанный для каждой шкалы альфа-коэффициент надежности Кронбаха показал в целом вполне приличный уровень внутренней согласованности, традиционный для личностных экспресс-опросников, в которых субшкалы содержат ограниченное число пунктов (менее 20):
Напомним, что строгим психометрическим требованиям, предъявляемым к эффективно работающему личностному тесту, соответствует значение альфа-коэффициентов выше 0,8.
В нашем же случае относительно низкий уровень значения коэффициентов надежности Кронбаха можно объяснить содержательной объемностью данных шкал: на каждую шкалу приходится по 15 разноплановых вопросов, что позволяет расширить область охвата исследуемых факторов, жертвуя вместе с тем высоким уровнем внутренней согласованности.
Особенно остро это сказалось на факторных шкалах "СОГЛАСИЕ" и "ОБУЧАЕМОСТЬ", по которой альфа-коэффициент оказался ниже 0,6.
3. Проверка репрезентативности
При переходе от выборки стандартизации (рис.1 - 300 человек) к выборке популяции (рис.2 - 660 человек) проявляется устойчивость конфигурации распределения тестовых баллов, что говорит о репрезентативности тестовой методики:
Рис.1. Выборка стандартизации (300 человек)

Рис.2. Выборка популяции (660 человек)
Помимо визуальной схожести этих распределений, использованный нами статистический хи-квадрат критерий Пирсона показал следующую степень сходства распределений:
Данные значения хи-квадрата попадают в промежуток неопределенности: когда нельзя однозначно принять или однозначно отвергнуть гипотезу о согласованности распределений.
Такой результат может быть обусловлен основным свойством экспресс-теста, а именно - малым количеством вопросов, работающих на каждую шкалу. Учитывая этот факт, результаты проверки репрезентативности можно признать удовлетворительными.
4. Проверка достоверности
Так как испытуемые, проходившие тестирование на сайте, находились в ситуации клиента (были заинтересованы в достоверных результатах), то с высокой вероятностью полученные результаты можно считать достоверными.
Однако в ситуации экспертизы (когда в результатах тестирования заинтересовано третье лицо), данные могут искажаться от вмешательства сознательных фальсификаций (лжи, неискренности испытуемого) или бессознательных мотивационных факторов. Чтобы избежать этого в версию, предназначенную для подобных случаев (B5splus), была добавлена шкала лжи (в данный момент эта версия проходит апробацию на нашем сайте) .
Полученные результаты являются свидетельством высокого качества и эффективности методики, что немаловажно, ведь профессиональный уровень специалиста, зачастую, определяется тем инструментом, которым он пользуется.
Однако, следует помнить, что даже мощный современный инструмент не гарантирует полного отсутствия ошибок. Для того чтобы избежать их, мало иметь компьютер и тестовую программу к нему. Обязательно нужен еще и опытный психолог, контролирующий выполнение теста. Так что наличие тестов, прошедших серьезную психометрическую адаптацию, вовсе не отменяет профессионализма и опыта психолога, призванного проверять правдоподобность тестовых результатов с использованием параллельных источников информации (включая собственное наблюдение, беседу и т.п.).
В последние годы автоматизированное тестирование стало трендом в области разработки ПО, в некотором смысле, его внедрение стало «данью моде». Однако внедрение и поддержка автоматических тестов – очень ресурсоемкая, соответственно, недешевая процедура. Повсеместное использование этого инструмента чаще всего ведет к значительным финансовым потерям без какого-либо значимого результата.
Как можно при помощи достаточно простого инструмента оценить возможную эффективность использования автотестов на проекте?
Что определяется как «эффективность» автоматизации тестирования?
Наиболее распространенный способ оценки эффективности (прежде всего экономической) является расчет возврата инвестиций (ROI). Вычисляется он достаточно просто, являясь отношением прибыли к затратам. Как только значение ROI переходит единицу – решение возвращает вложенные в него средства и начинает приносить новые.
В случае автоматизации под прибылью понимается экономия на ручном тестировании . Кроме того, что прибыль в данном случае может быть и не явной – например, результаты нахождения дефектов в процессе ad-hoc тестирования инженерами, время которых высвободилось за счет автоматизации. Такую прибыль достаточно сложно рассчитать, поэтому можно либо делать допущение (например +10%) либо опускать.
Однако не всегда экономия является целью внедрения автоматизации. Один из примеров – скорость выполнения тестирования (как по скорости выполнения одного теста, так и по частоте проведения тестирования). По ряду причин скорость тестирования может быть критической для бизнеса – если вложения в автоматизацию окупаются полученной прибылью.
Другой пример – исключение «человеческого фактора» из процесса тестирования систем. Это важно, когда точность и корректность выполнения операций является критической для бизнеса. Цена такой ошибки может быть значительно выше стоимости разработки и поддержки автотеста.
Зачем измерять эффективность?
Измерение эффективности помогает ответить на вопросы: «стоит ли внедрять автоматизацию на проекте?», «когда внедрение принесет нам значимый результат?», «сколько часов ручного тестирования мы заместим?», «можно ли заменить 3 инженеров ручного тестирования на 1 инженера автоматизированного тестирования?» и др.
Данные расчеты могут помочь сформулировать цели (или метрики) для команды автоматизированного тестирования. Например, экономия X часов в месяц ручного тестирования, сокращение расходов на команду тестирования на Y условных единиц.




